Kubeflow Inference Service
Launch a kubeflow Inference Service and demonstrate knative scale
In this demo you will:
- Deploy a sklearn KfServing Iris Classifer
- Run a load test to show knative autoscaling
- Create a canary XGBoost model
- Promote the Canary
- Delete the model
From the Deploy UI create a server:
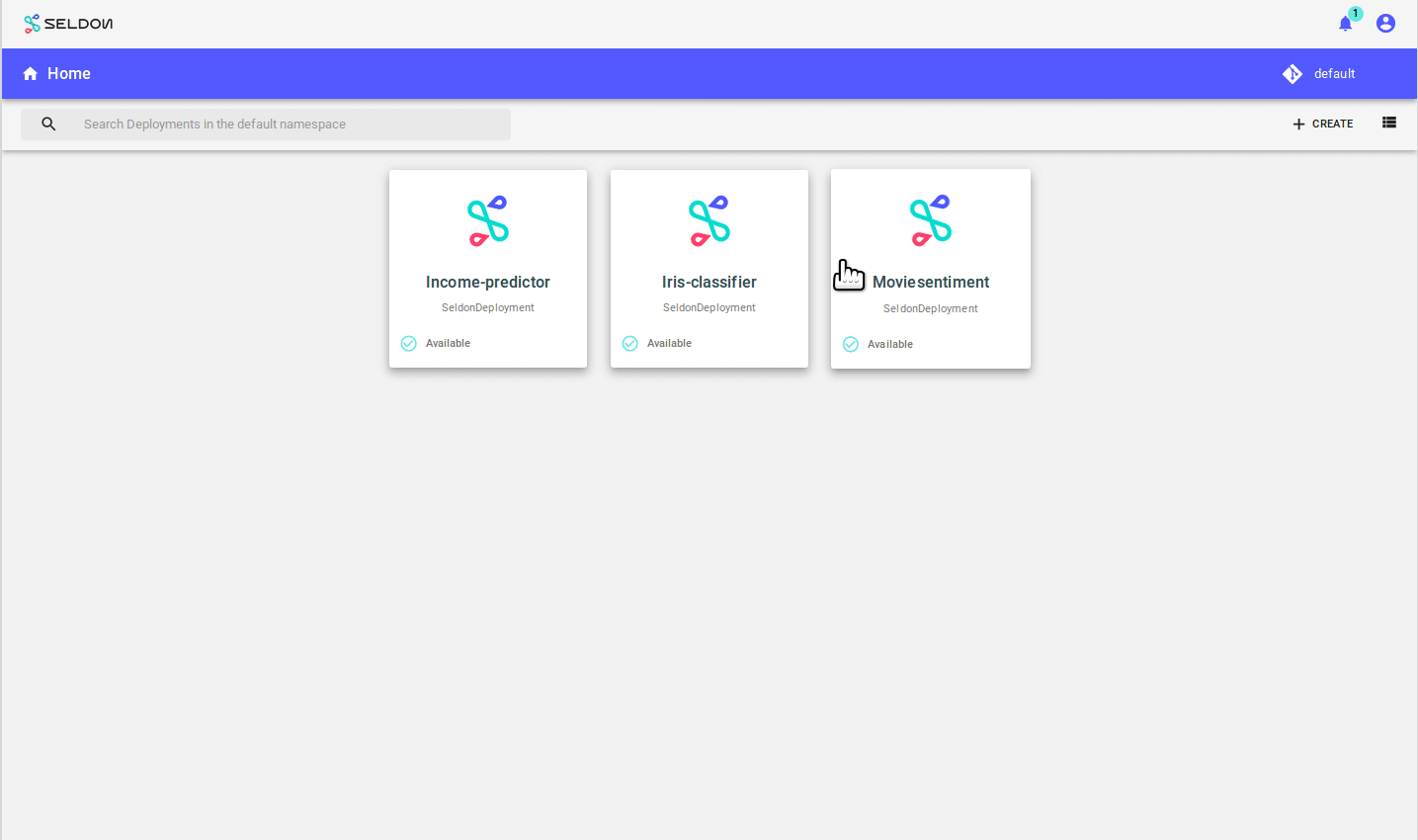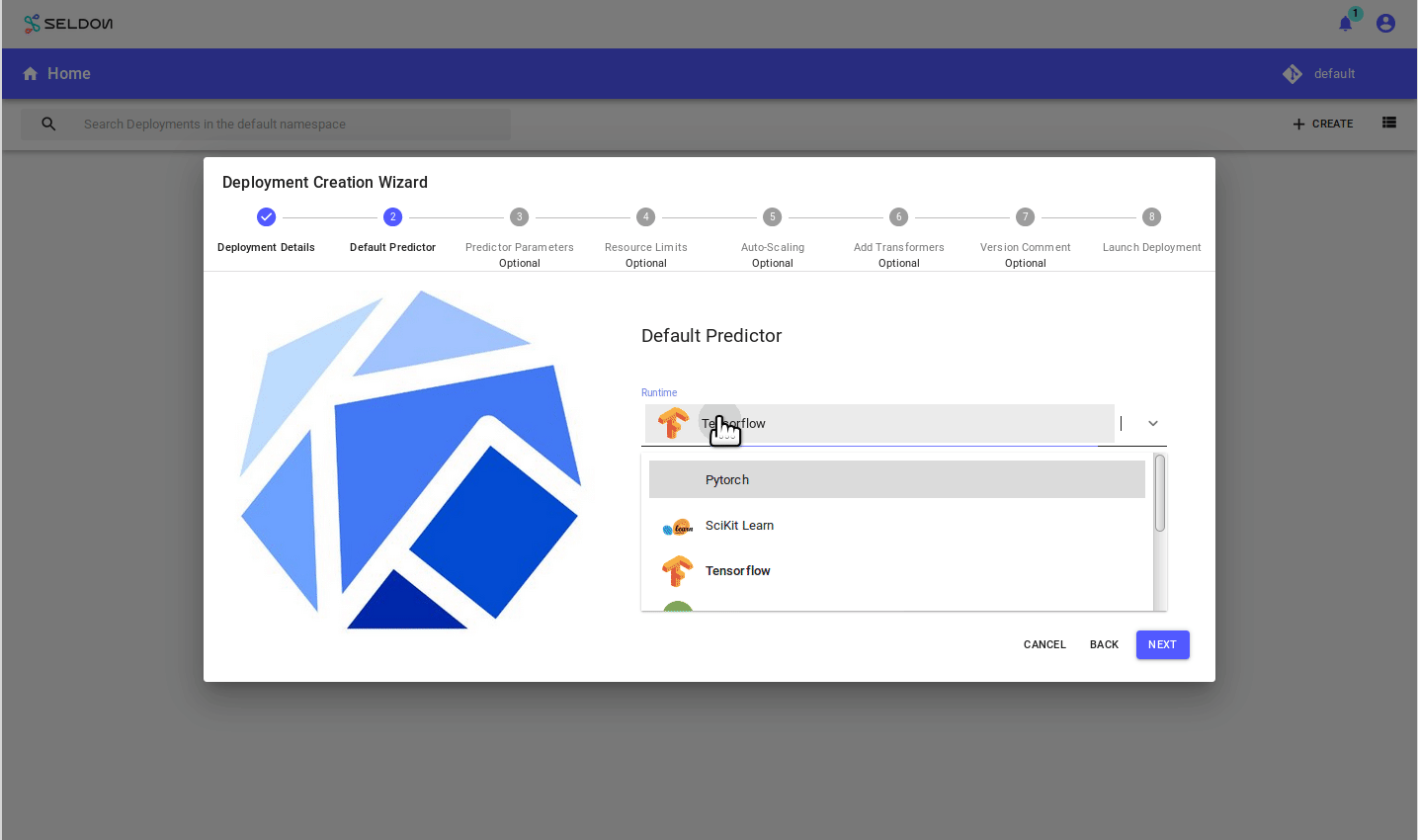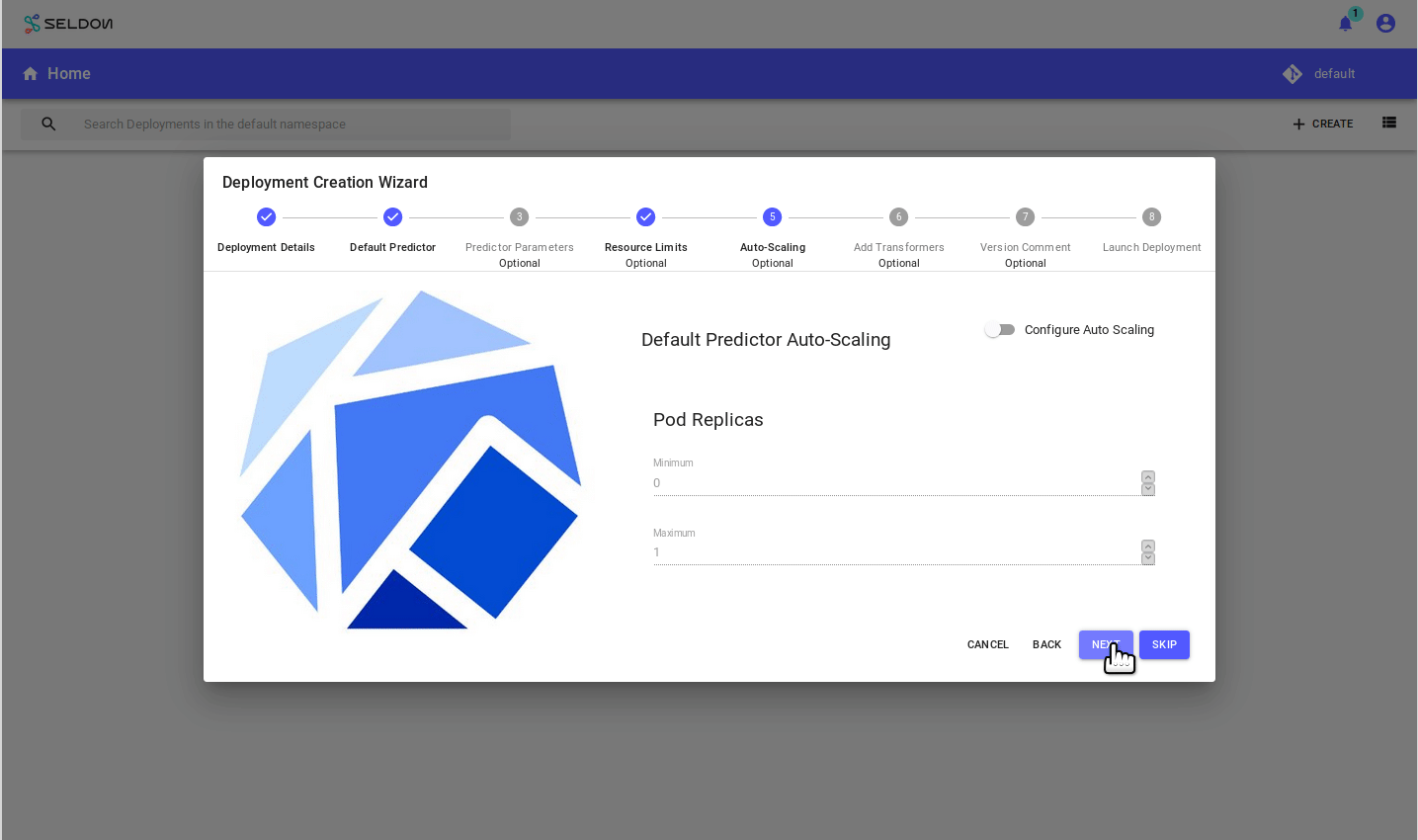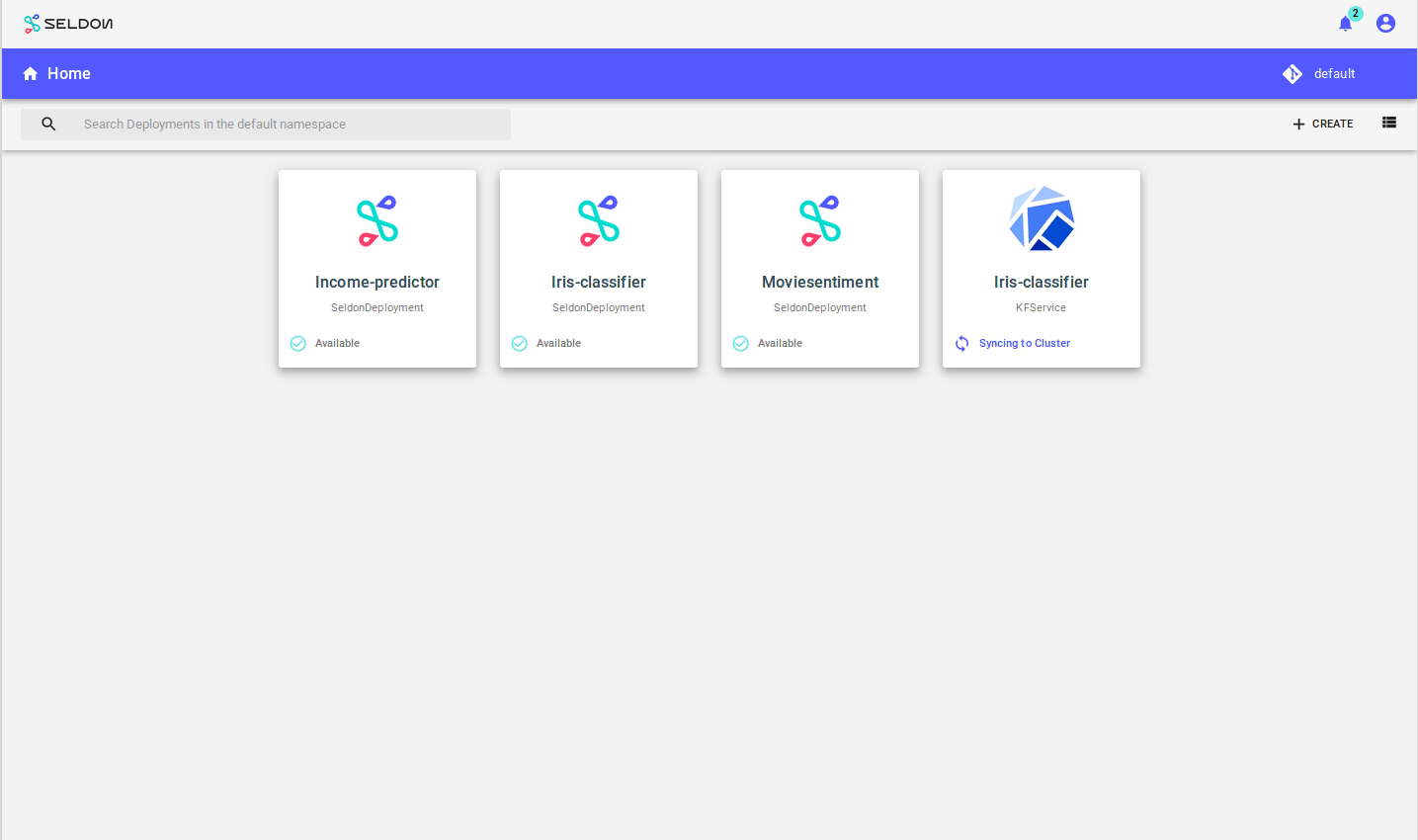
Use the model url:
gs://kfserving-samples/models/sklearn/iris
Run a Load Test
When the deployment is ready click on it and “Start a Load Test”.
Set the duration to 60 secs and the number of connections to 10.
Use the request.json file in this folder:
{
"instances": [
[6.8, 2.8, 4.8, 1.4],
[6.0, 3.4, 4.5, 1.6]
]
}
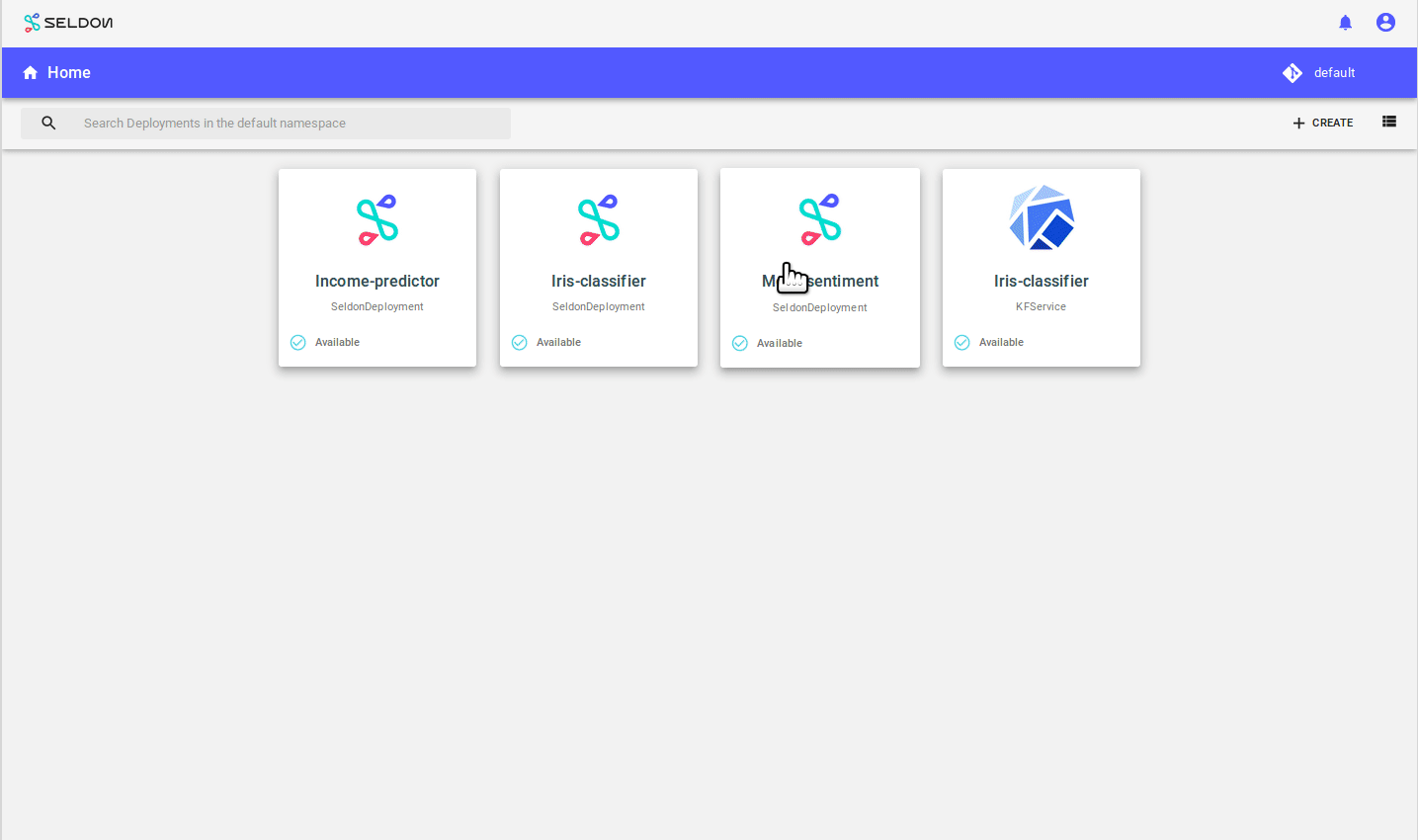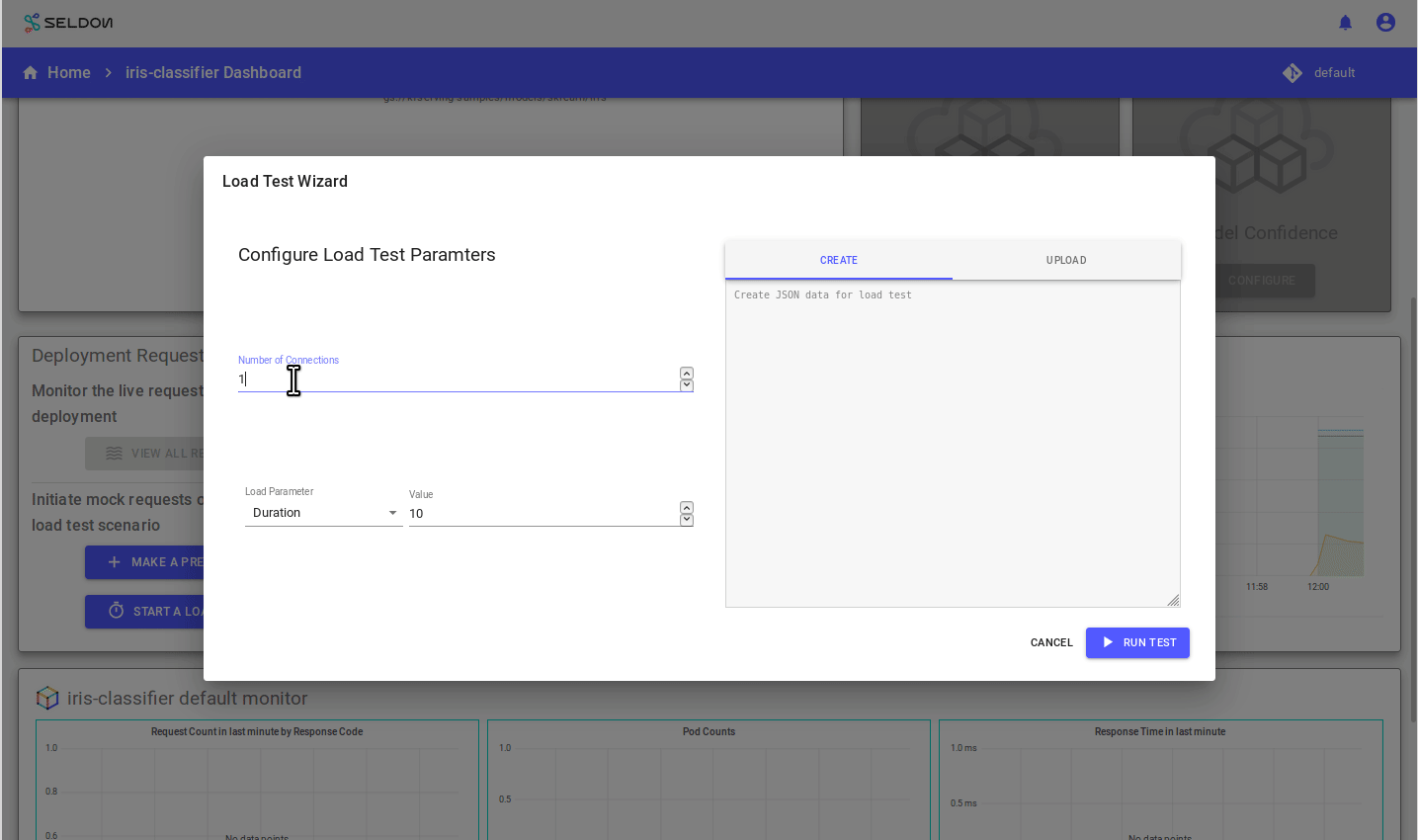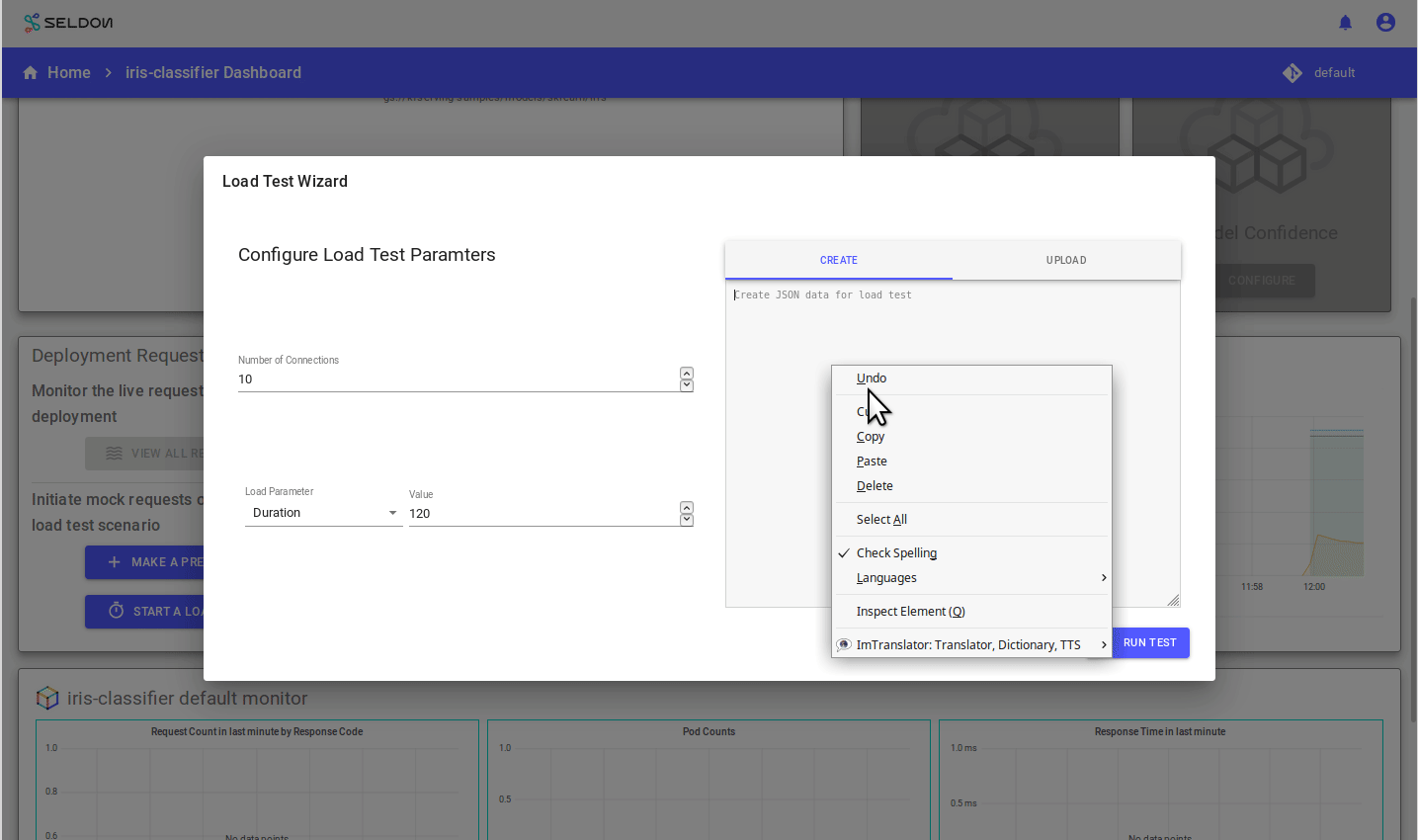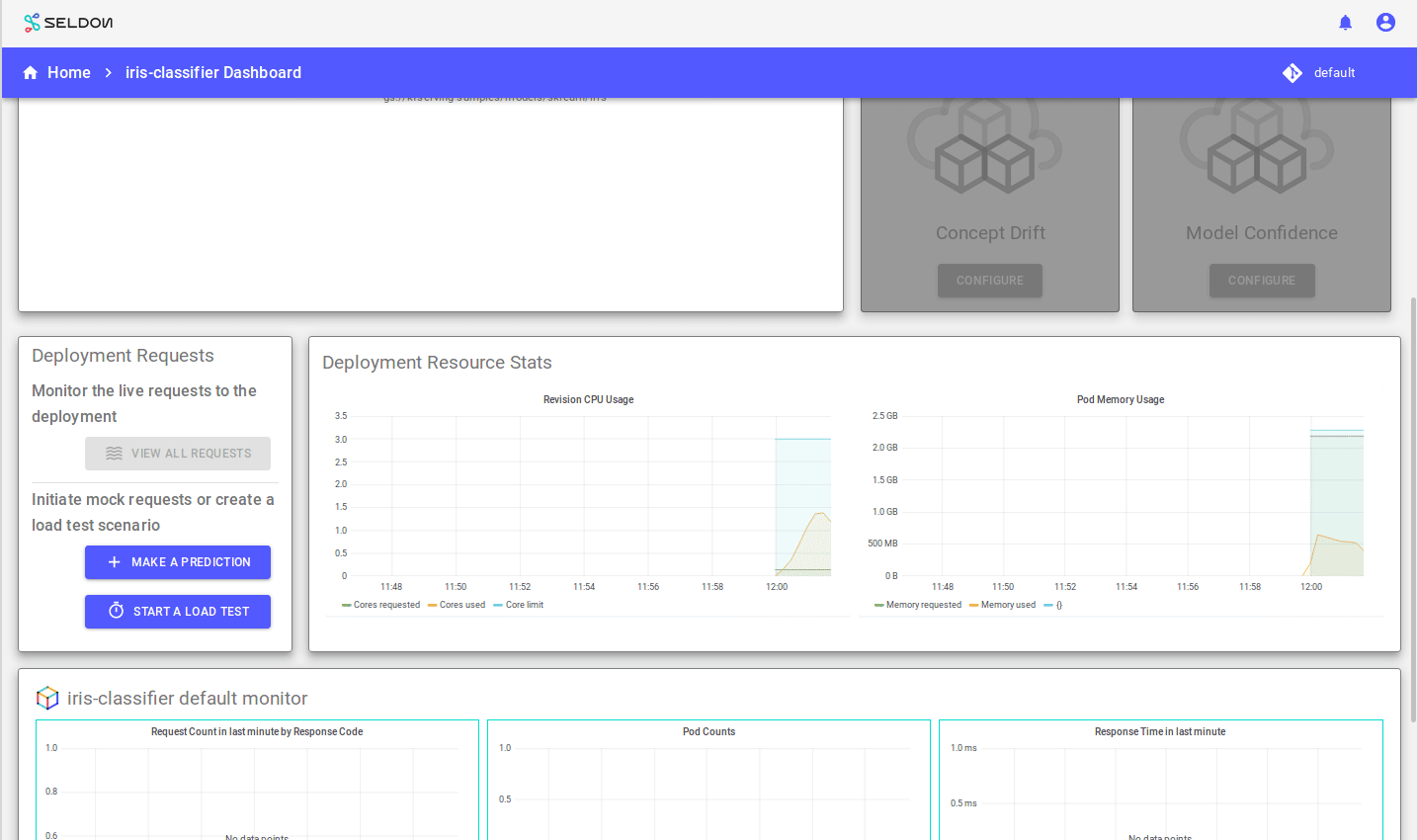
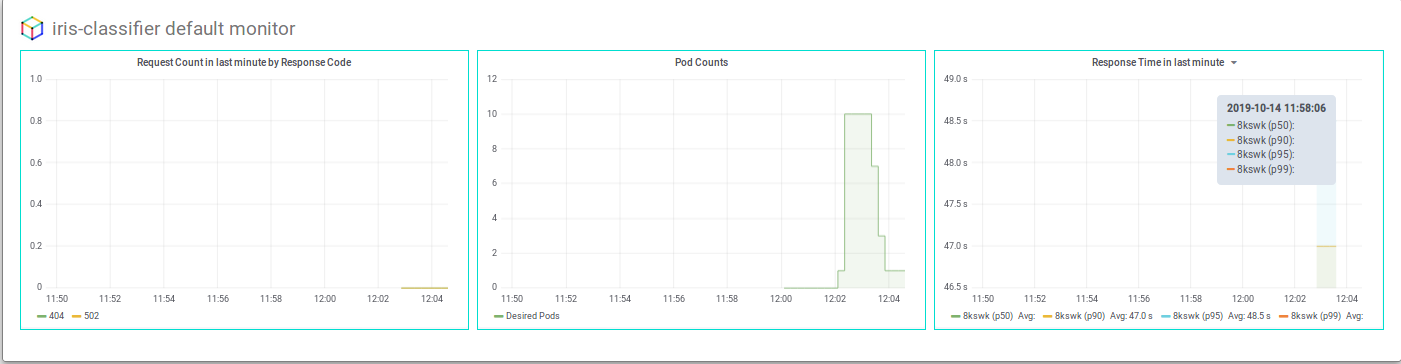
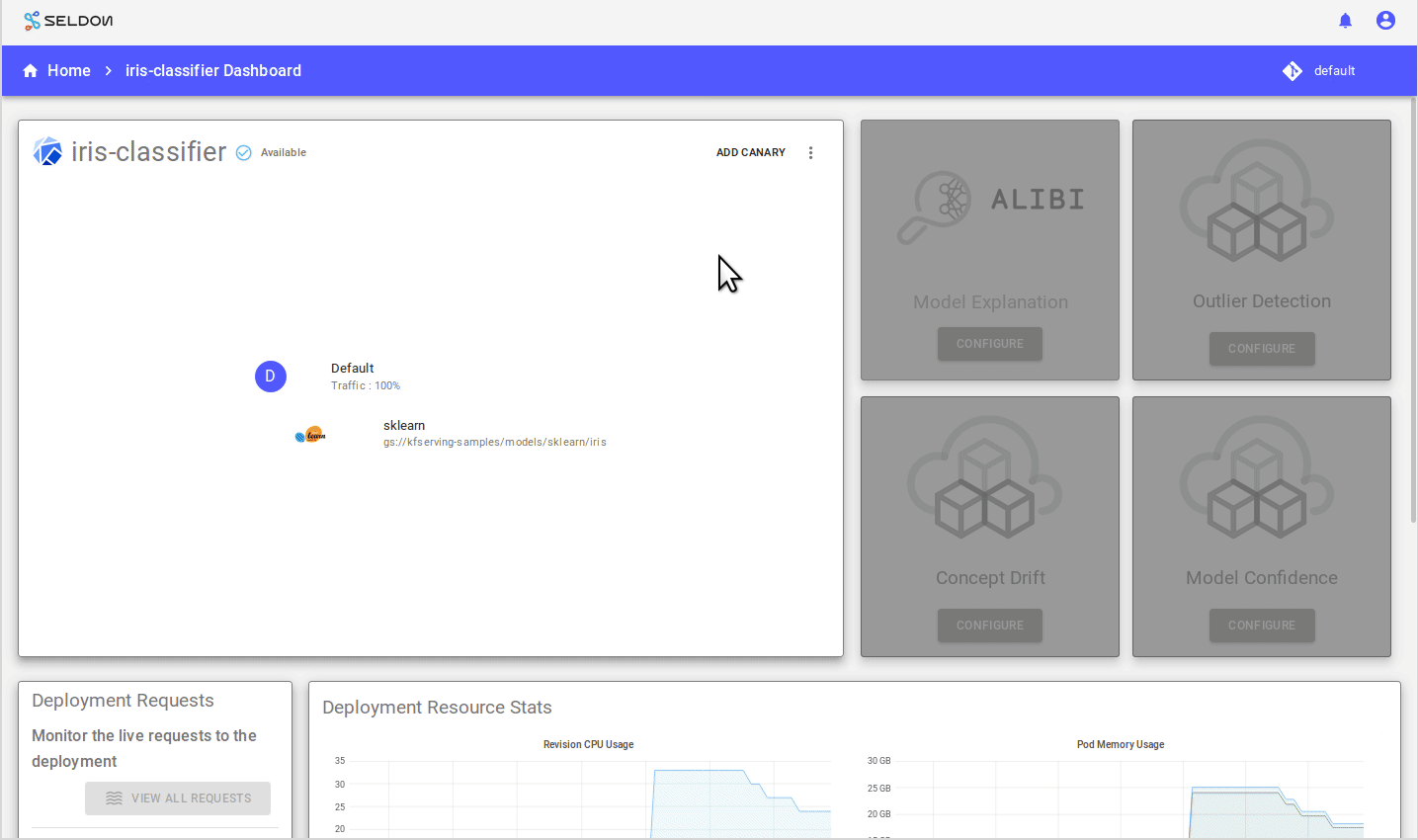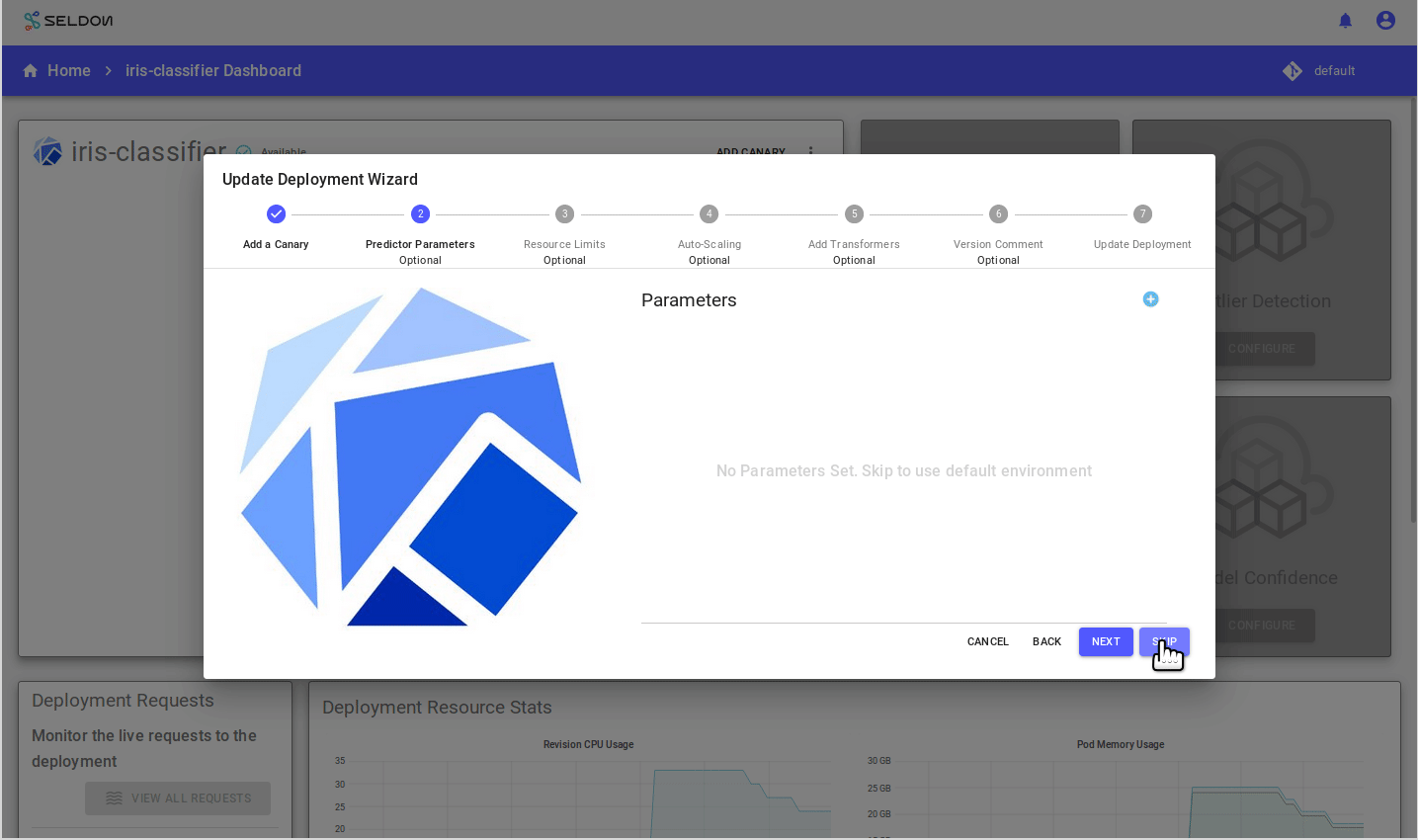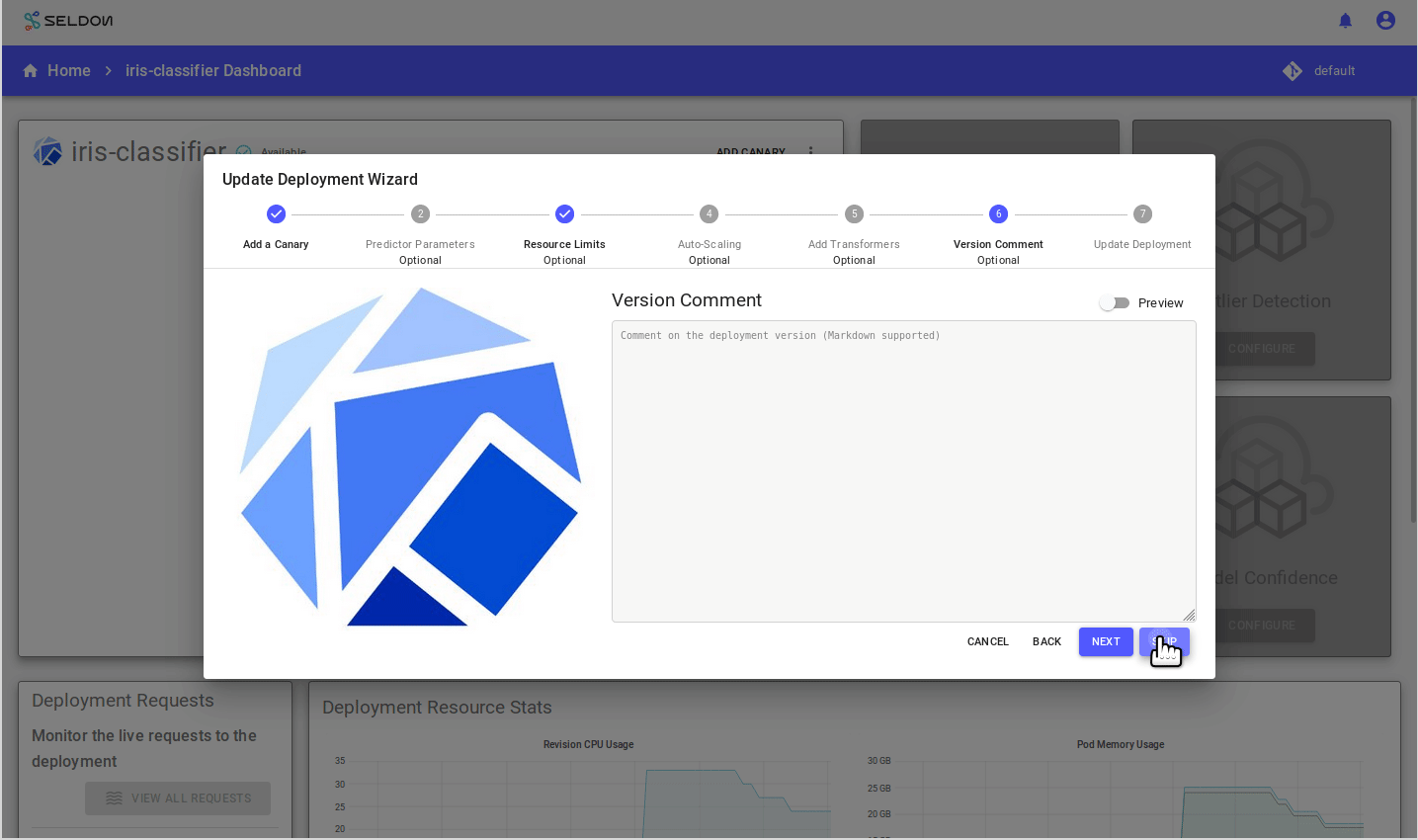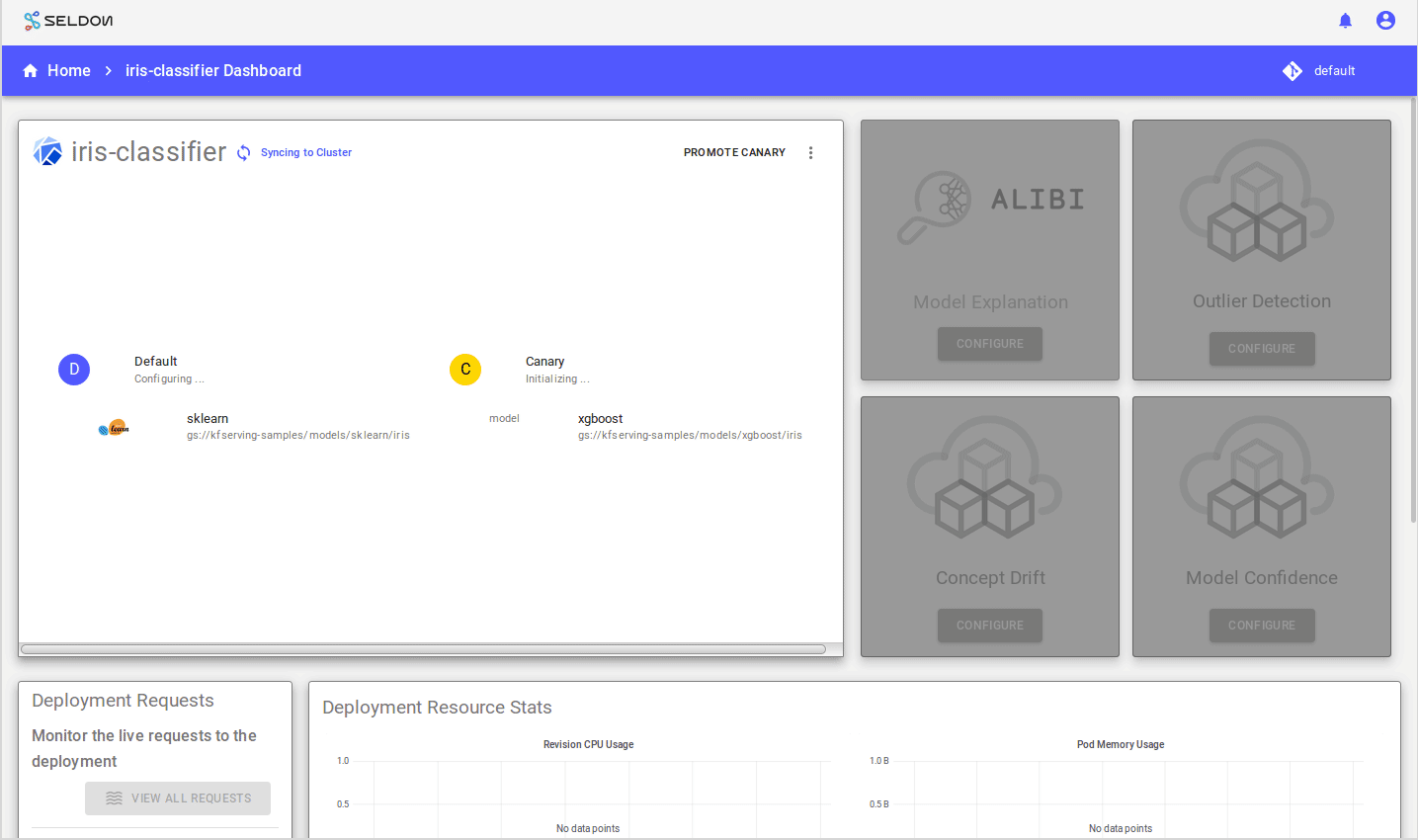
You should see pod counts scale up and then down, something like:
Adding a Canary
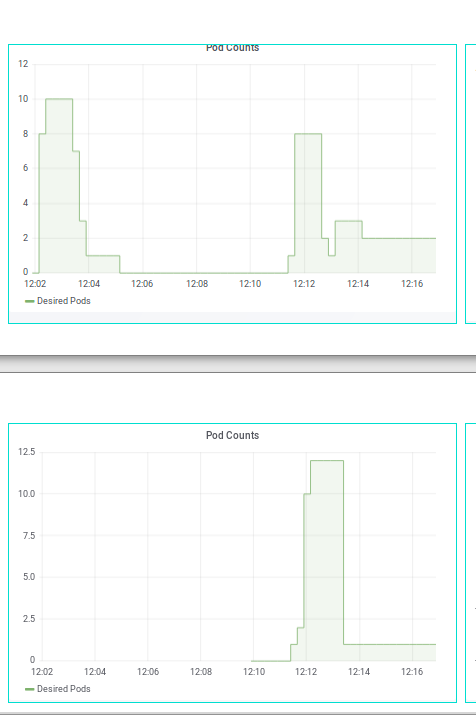
Now follow the “Add Canary” wizard and add an XGBoost canary:
Use the XGBoost Iris model whose saved Booster is stored at:
gs://kfserving-samples/models/xgboost/iris
One the canary is running you can rerun the load test and see traffic split between both.
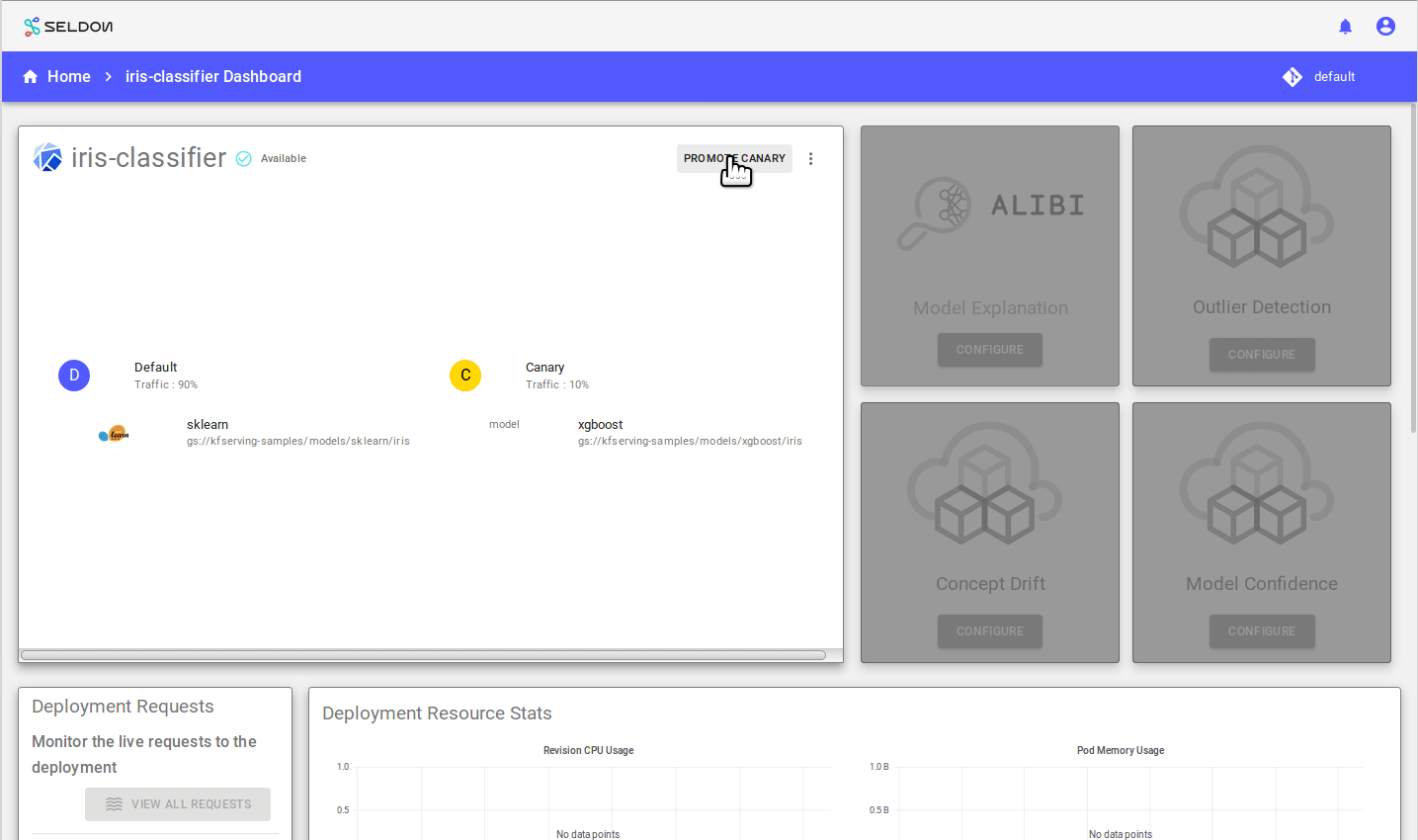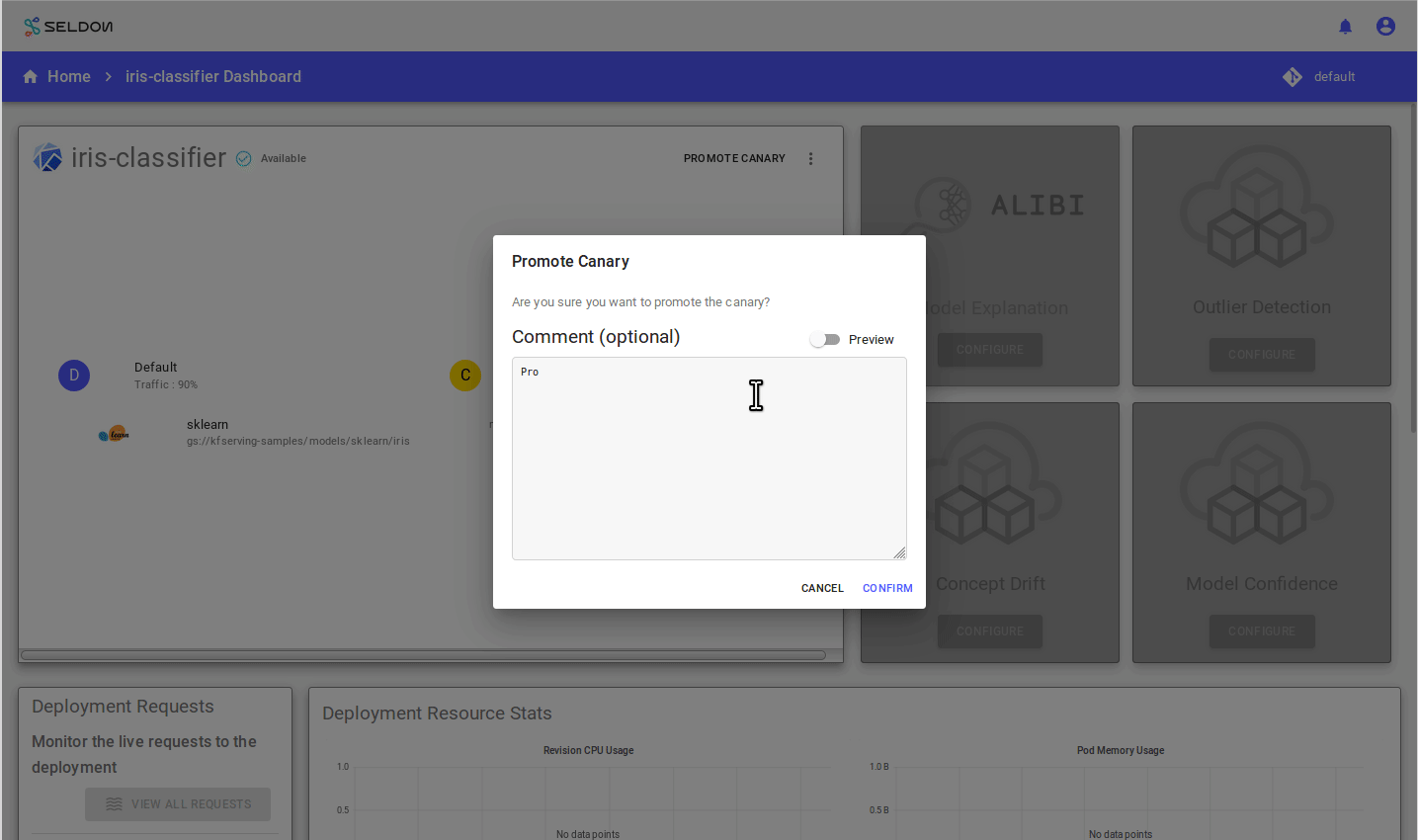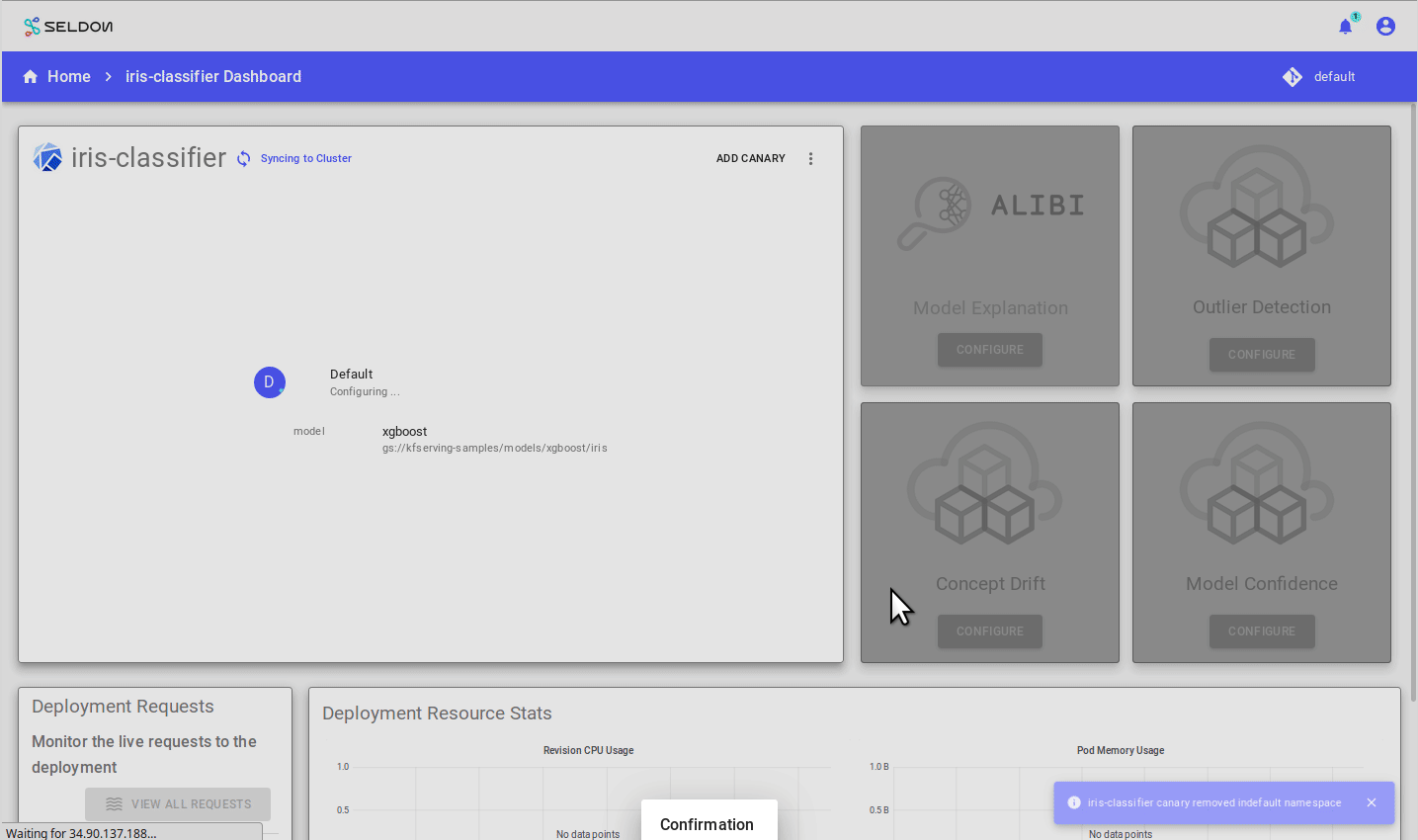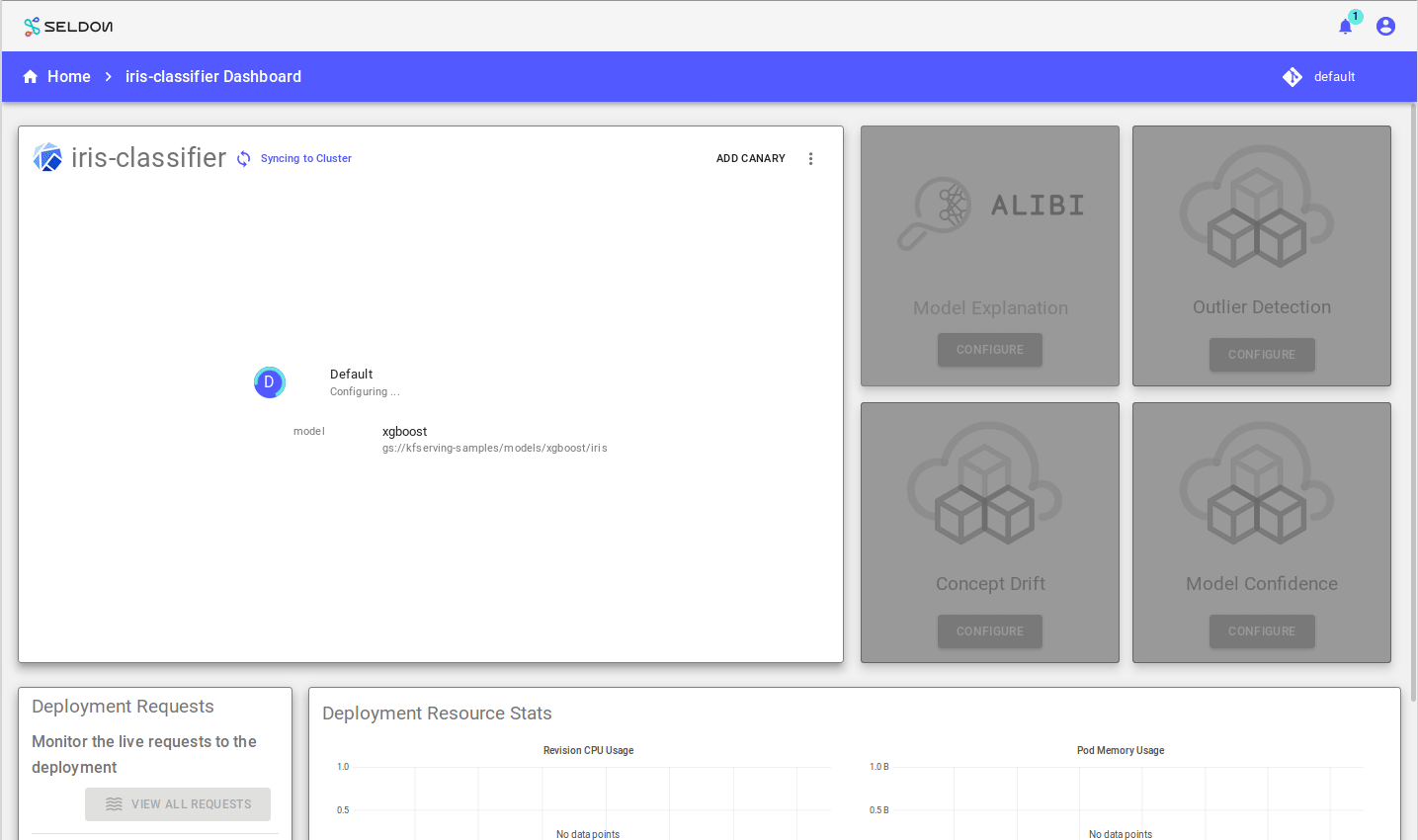
To promote canary press the “Promote Canary” button
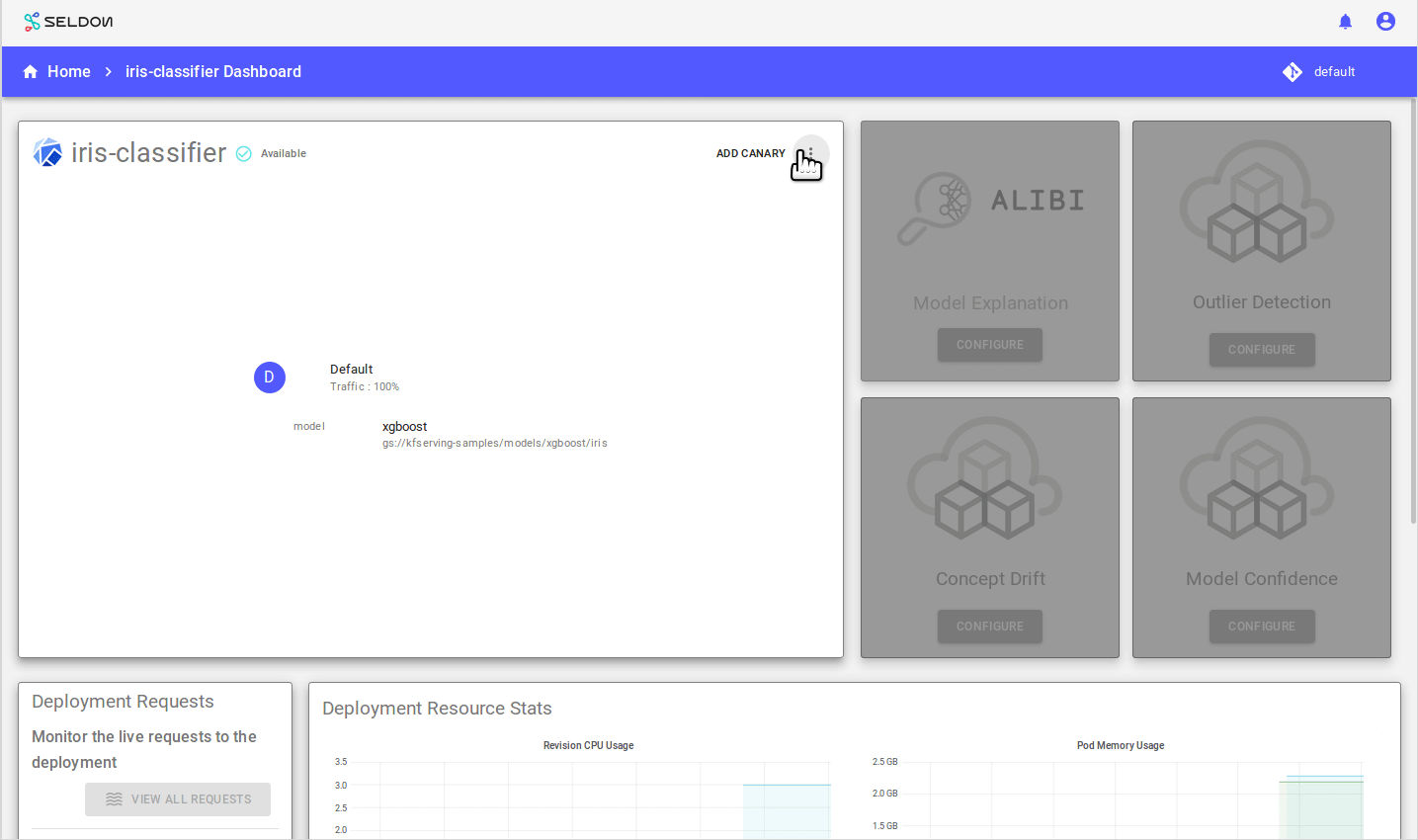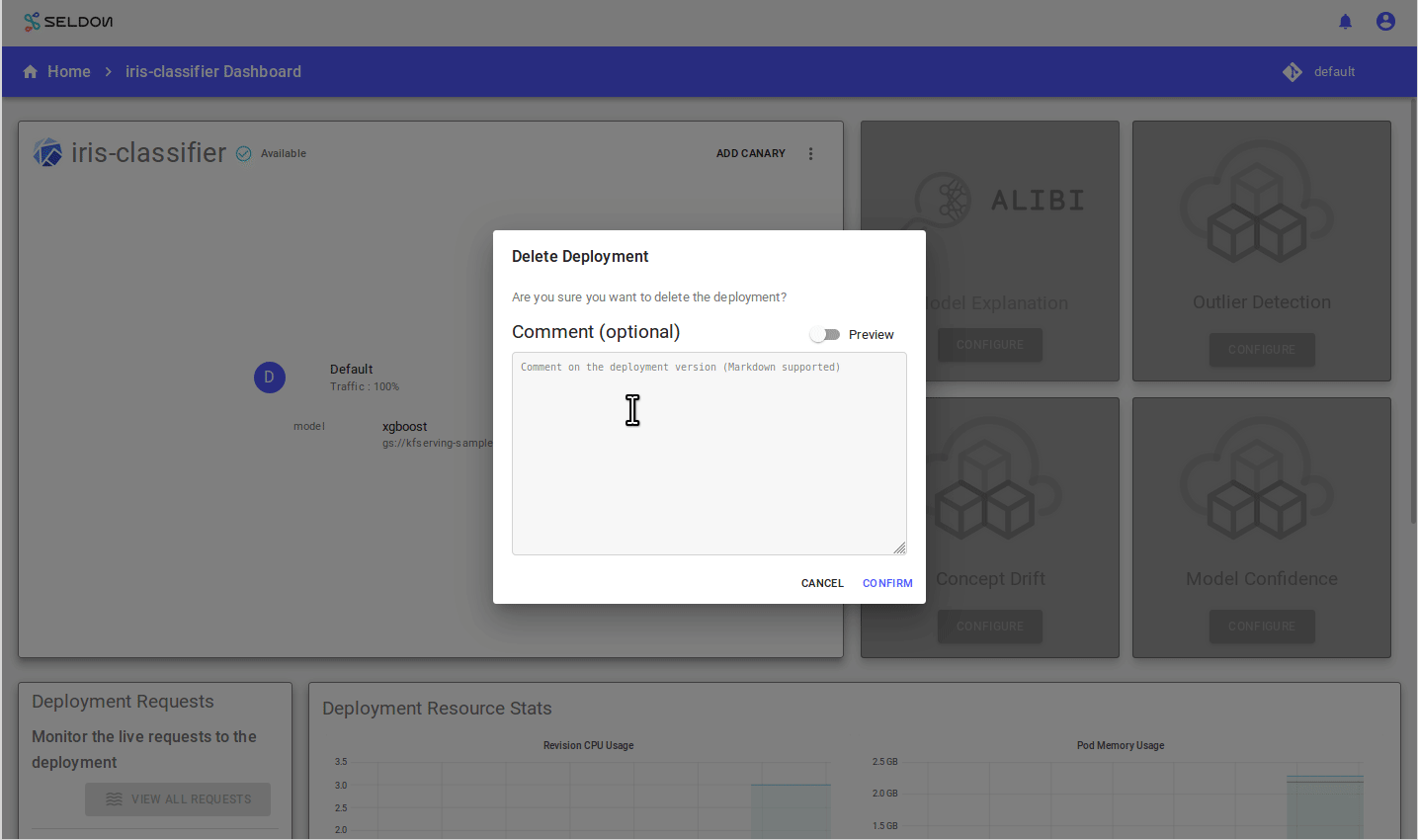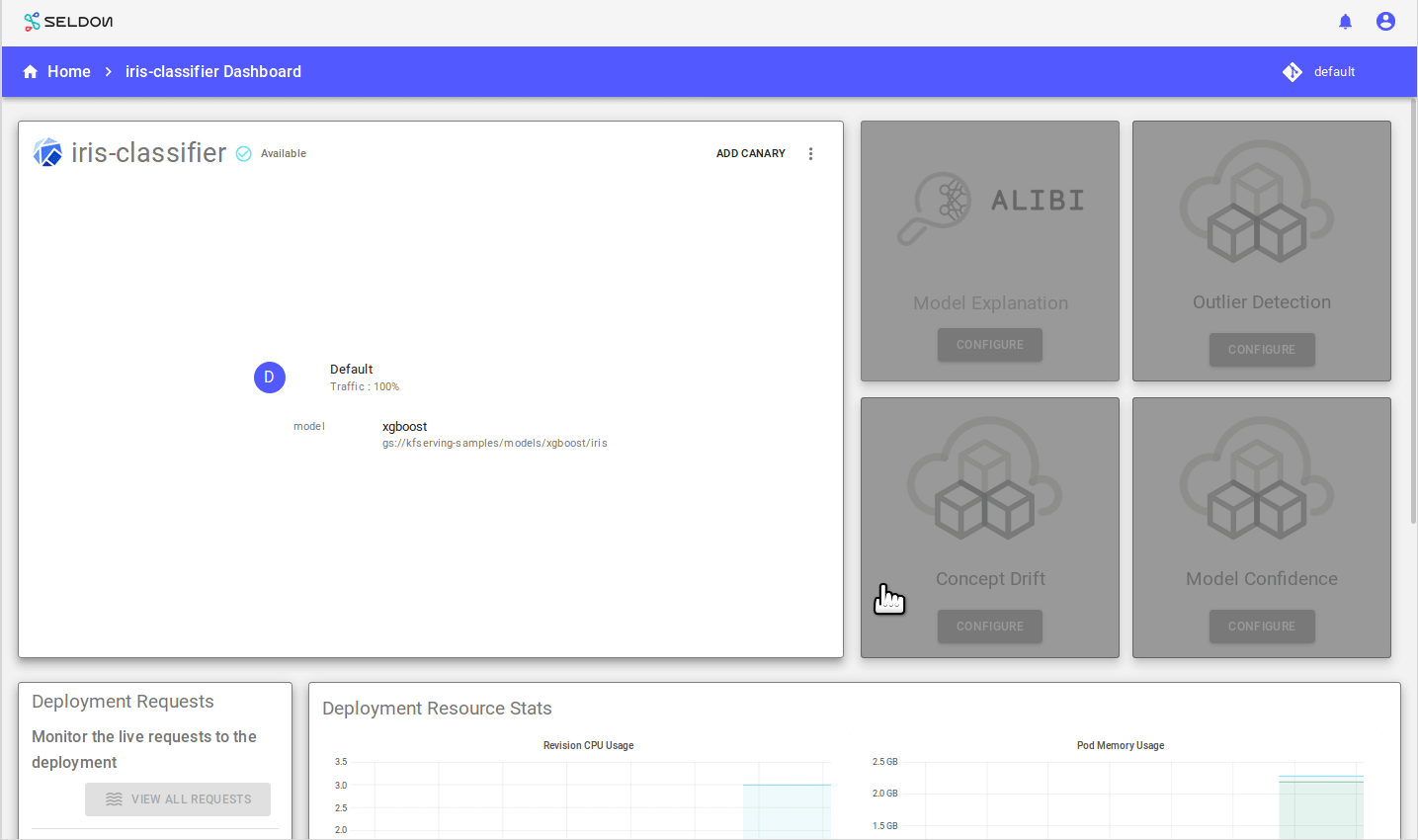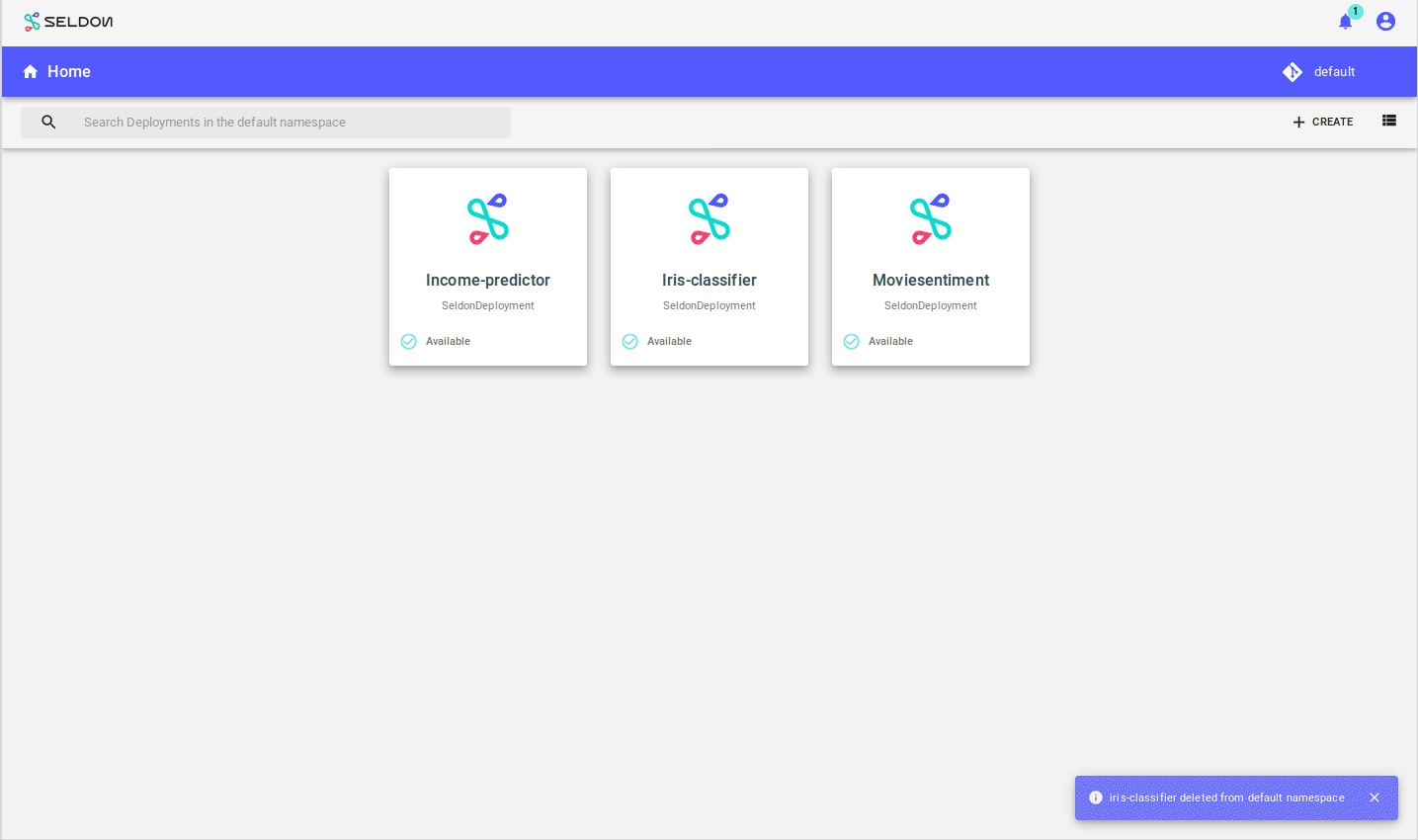
Delete the Deployment
Finally, you can delete the model.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.
Last modified October 29, 2019: Reorganizing project structure and adding WIP image explanations (8bfc877)